
The main idea behind this research project was to explore communication differences in disparate populations during the 2016 election cycle. The populations in question include supporters and dissenters of the main candidates (namely Hillary Clinton and Donald Trump). The data used was two Terabytes of Twitter data collected over six months before the results of the election came out.
By comparing the differences between the communication of the two candidates supporters and dissenters, claims about the type of rhetoric they champion and how that bodes for the future of the United States can be made. To compare these differences, creation of word networks centered around each candidate’s name was the goal. To see how the candidate’s name was used in tweets, the sentiment of said tweets, and the uniqueness of each tweet were all factors that I wished to consider in building the network.
A key ideal that my PI and I wanted to maintain was impartiality in this project. To do so, the creation of the aforementioned networks would be done solely by the data. That is to say, the word rankings would be done algorithmically and without human input. The idea of using word embeddings came to mind. Using the Word2Vec embedding, finding a similarity between two words was easy to obtain. It so happens that Word2Vec takes the number of occurances, distance from specific other words, and uniqueness of the word in the entire dataset when creating the embedding.
The final architecture of the word network was to have the candidates name in the center, have the top N closest words to their name connected to center word, and have the top N closest words to those words connected to them ad infinitum. This is difficult to visualize with words, so I have an example network pictured here for Trump dissenters:
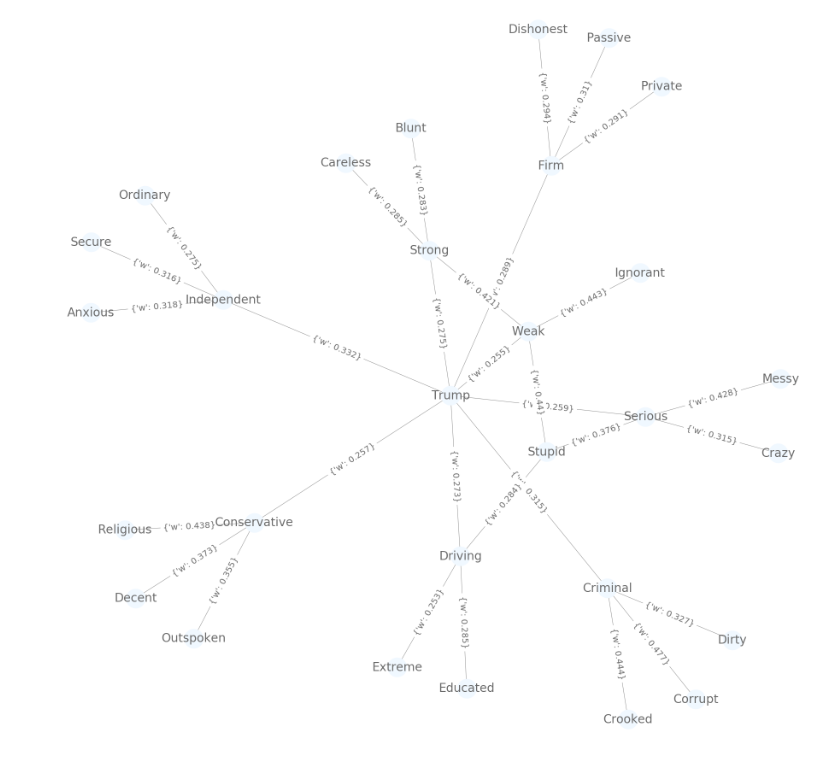
For visualization purposes N = 10 for the words connected to the center, and N = 3 for the next layer afterwards (having thousands of words connected was not possible to fit on my poster, sadly). It can also be seen that words in the network contradict one another (such as strong and weak). This is partially due to the inherent error in data collection (it is impossible to perfectly separate supporters and dissenters, so the tweets will be skewed towards one population at best). It is also worth mention that humans are multi-faceted, and although they tend to be described in one particular way, they may champion other ideals at times that would normally be out of character.
By looking at the total degree of nodes in the network, it is easy to observe candidates that have supporters with limited/expansive vocabularies. Observing the words themselves gives an indication of sentiment that a candidate is associated with and propagates. Therefore, seeing a candidate’s supporters profess hate speech or neutral/positive speech gives insight into the character of the candidate and the type of base they invite.
To look at the code for this project, look here.